Introduction
Dependencies makes it easy for developers to understand the architecture of their app. We also wanted to provide a simple solution to objectively measure the quality and the complexity of the architecture. That’s the reason why we developed a new mathematical formula in the graph theory that we called Software Entropy.
Dependencies calculates and displays the Software Entropy of your app. In the following screenshot, the analyzed iOS framework has a Software Entropy with a value of 25. This low value clearly indicates a well structured code:
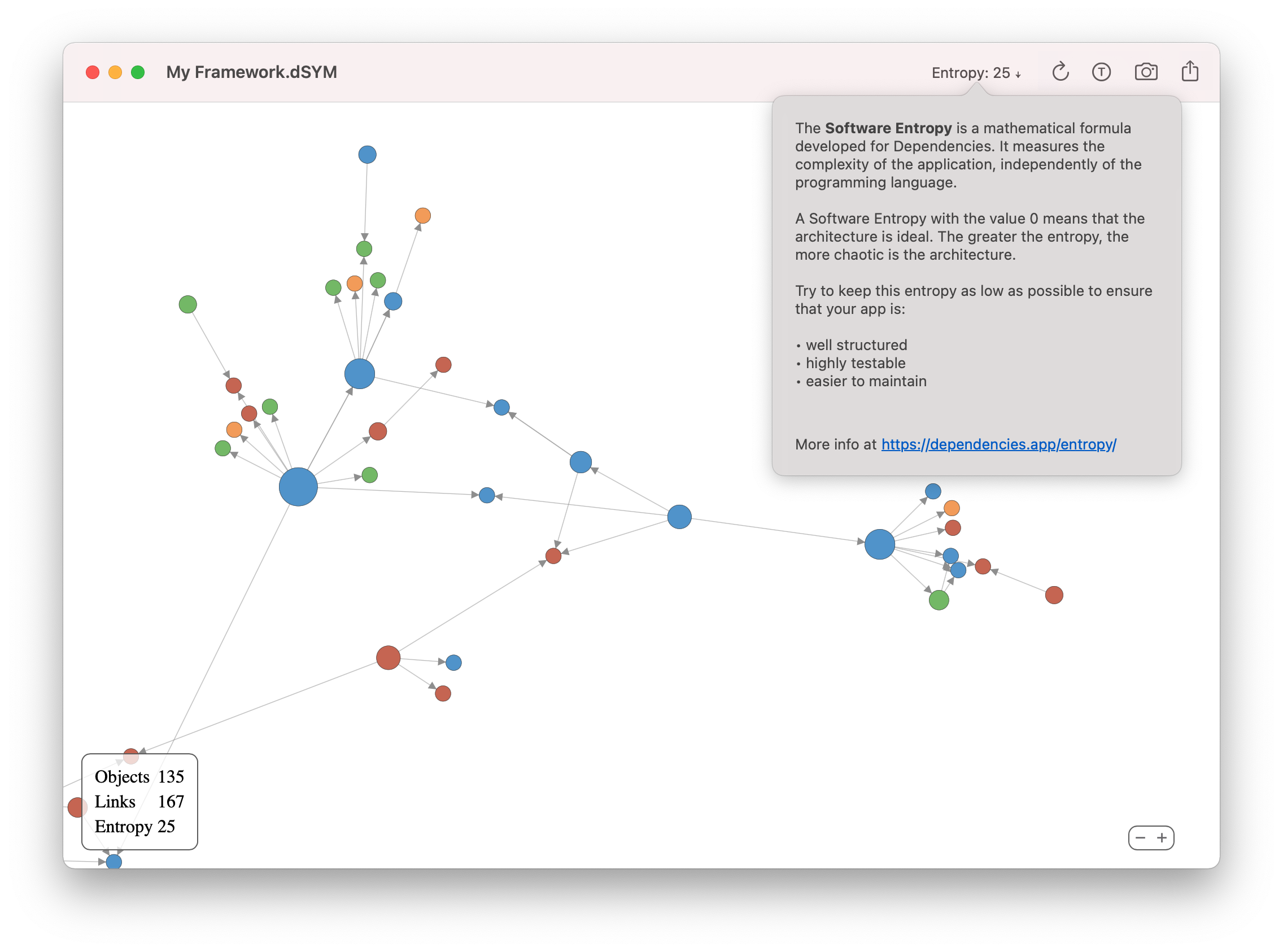
This paper describes the mathematical concept behind the Software Entropy and how to calculate it.
Why the need for a new mathematical formula?
Dependencies is able to extract the architecture of your app and create an interactive graph. From this graph, we want to calculate an objective score indicating the complexity of the architecture. This score needs to be agnostic to the programming language, i.e. you should be able to compare the score of an app written in Swift with the score of an app written in C++ or Objective-C.
There is a fairly well-known technique to measure the complexity of a program: in a paper titled “A Complexity Measure”, Thomas McCabe introduced the Cyclomatic Complexity, a mathematical formula to calculate the complexity of a program control flow. This was in… 1976! You can read the original publication here.
However the Cyclomatic Complexity has various limitations which makes it unsuitable for our use case. It was defined with Fortran in mind at a time where Object-Oriented Programming was not widely popular: Objective-C and C++ were both developed around 1985…
Therefore the Cyclomatic Complexity is really limited to calculate the complexity of control flow graph, i.e. if-else statements. This technique is still useful for example to measure the complexity of a single function. This is relevant for unit testing and code coverage because it provides a good indicator on the number of test cases required to cover all branches.
Since we could not find a mathematical concept in the graph theory to give a meaningful complexity score for the architecture of an object-oriented software, we decided to define our own mathematical concept to fill this gap.
Definitions
Nodes and links
In the graph theory, a graph is a structure containing nodes linked together by links:
- the nodes are sometimes called vertices or points.
- the links are sometimes called edges or lines. They join 2 nodes.
Here is a graph with 5 nodes and 5 links:
Directed graphs
For the Software Entropy, we will only deal with directed graphs: a link between the node 1 and the node 2 means that the node 1 depends on node 2 but node 2 doesn’t depend on node 1:
A graph with 2 nodes (1 and 2) and 2 links (1→2, 2→1) is possible but loops are not allowed (a node can’t link to itself):
Components
An important concept is the concept of components in a graph. To calculate the Software Entropy, we are only interested by weakly connected components, i.e. we ignore the direction of the links.
This graph with 7 nodes and 7 links is composed of 2 components:
Software Entropy formula
The Software Entropy for a graph with one single component is calculated by the formula:
Software Entropy = L - N + 1
where:
- N is the number of nodes
- L is the number of links between nodes
We can generalize this formula for a graph with C independent components as being the sum of the Software Entropy of each component:
Software Entropy = ∑(LC - NC + 1)
where:
- NC is the number of nodes in the component C
- LC is the number of links between nodes in the component C
Property: the Software Entropy is a positive value
One interesting property of the Software Entropy is that its value is always positive:
Software Entropy >= 0
- An empty graph (no component, no link, no node) has a Software Entropy of 0.
- A graph containing a single node and no link has a Software Entropy of 0 - 1 + 1 = 0.
- A component of N nodes contains at least (N - 1) links. As a consequence the Software Entropy for a component is positive.
- The Software Entropy for a graph with multiple components is the sum of the Software Entropy of each component. As a consequence the Software Entropy for any graph is positive.
Meaning of the Software Entropy for the app architecture
In a well-structured app, you want to have separate components. You absolutely want to avoid that each class knows about all the other classes in your app.
If you represent the architecture of your app with a graph, each node representing a class or structure and each link representing a dependency between 2 classes, you want to minimize the number of links in the graph. The more dependencies you have between classes, the more chaotic your architecture is.
As a result, a well-structured architecture will tend to have a smaller Software Entropy than a poorly designed application.
A Software Entropy with the value 0 means that the architecture is ideal and only the minimum amount of links between classes are used. The greater the entropy, the more chaotic the architecture is. The Software Entropy can be use as an objective metric to ensure that your app is:
- well structured
- highly testable
- easy to maintain
Examples
A graph with a single node has a Software Entropy of 0 (0 link - 1 node + 1 = 0):
A graph with 2 nodes linked with 1 link has a Software Entropy of 0 (1 link - 2 nodes + 1 = 0):
A graph with 2 nodes linked with 2 links has a Software Entropy of 1 (2 links - 2 nodes + 1 = 1):
The following graph containing 4 nodes has a Software Entropy of 0 (3 links - 4 nodes + 1 = 0). It could correspond to the composition pattern in the Object Oriented concept:
The following graph containing 4 nodes has a Software Entropy of 0 (3 links - 4 nodes + 1 = 0). It could correspond to the inheritance pattern in the Object Oriented concept:
The following graph containing 4 nodes has a Software Entropy of 1 (4 links - 4 nodes + 1 = 1). It could correspond to the concept of Retain Cycle:
The following graph contains 2 components and has a Software Entropy of 0 (3 links - 4 nodes + 1) + (3 links - 4 nodes + 1) = 0:
The following graph contains 2 components and has a Software Entropy of 3 (5 links - 4 nodes + 1) + (4 links - 4 nodes + 1) = 3: